쿼리 튜닝의 이해
쿼리 튜닝에 대해서
쿼리 튜닝은 데이터베이스 성능 최적화를 위해 질의문을 데이터베이스 옵티마이저가 더 나은 실행계획을 세울 수 있도록 하는 것을 말합니다.
쿼리 튜닝을 왜 해야 하는지 굳이 알아야 하는가에 대한 이야기를 하는 백엔드 개발자들도 봤지만, 개인적인 생각으로는 서버와 데이터베이스를 다루는 입장에서 당연히 알아야 하는 부분이라고 생각합니다. 그리고 쿼리 튜닝을 알면 자연스럽게 쿼리 그 자체에 대해서도 알고 native query, ORM에 대해서도 더 쉽게 이해할 수 있기 때문입니다.
1. Query Processing
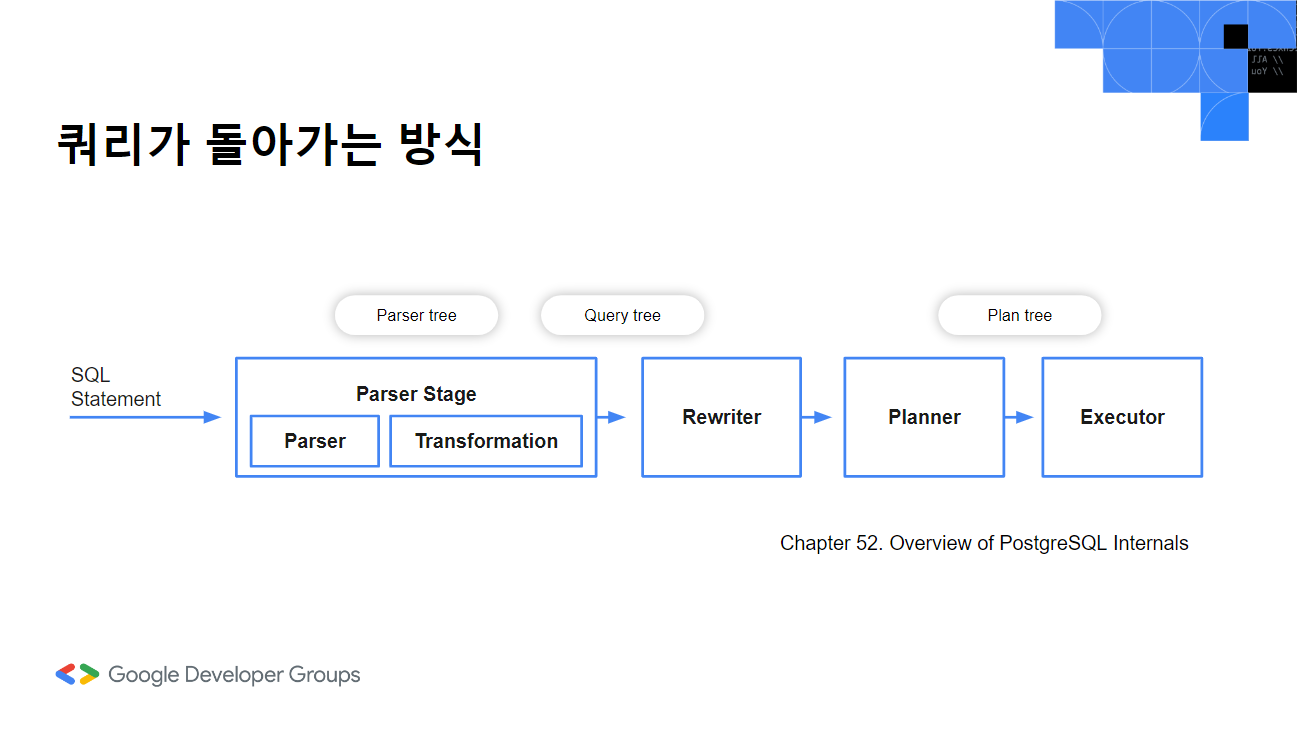
Postgresql에서는 parser stage가 있는데 여기서 parser로 쿼리를 parse tree로 만들고 transformation 과정으로 parse tree 의미를 분석해 query tree를 만듭니다. (문서를 기준으로 작성했고 이 부분을 analyzer로 표기한 자료들도 있습니다.) 그리고 rewriter는 정해진 규칙 시스템에 따라 쿼리 트리를 다시 작성합니다. planner는 쿼리 트리를 바탕으로 실행될 plan tree를 만듭니다. 이 부분이 우리가 흔히 말하는 옵티마이저에 해당하는 부분입니다. 마지막으로는 excutor로 plan tree 생성 순서대로 쿼리를 실행합니다.
Parser
먼저 쿼리를 바탕으로 parser에서는 구문 분석을 진행합니다. sql 문법에 맞는지 확인하는 단계입니다. 쿼리의 내용 자체에는 관심이 없어요.
Transformation
이렇게 트리가 만들어진 후에 transformation 과정을 통해 query tree가 만들어집니다. 이전에는 구문 분석만 했다면 이번에는 실제 쿼리에 있는 테이블, 컬럼이 실제로 있는 유효한 내용인지를 확인할 수 있는지 여부를 확인하는 과정을 거치게 됩니다. 트랜잭션 과정에서 시스템 카탈로그를 확인하기 위해 두 부분이 parser와 나눠져 있는데, 여기서 시스템 카탈로그는 데이터베이스의 메타 데이터를 담은 장소라고 할 수 있습니다.
Rewriter
rewriter 단계에서는 query tree를 바탕으로 rule system을 구현하는 단계입니다.
Planner
planner 단계는 rewriter 단계에서 받은 query tree를 가지고 데이터를 찾아 실행계획을 위한 plan tree를 만듭니다. 실행계획에 따른 비용을 계산해서 효율적인 방식을 사용합니다. 공식문서에 따르면 다수의 조인으로 인한 과도한 시간과 메모리가 소요되기 때문에 일정 수의 join을 넘어가는 경우 Genetic Query Optimizer를 사용한다고 합니다.
Exector
exector 단계에서는 plan tree 의 노드를 순차적으로 수행해서 데이터를 가공합니다. explain analysis 처리한 쿼리 결과를 보면 다음과 같은 자료를 얻을 수 있습니다. WindowAgg(윈도우 어그리게잇)으로 비용, 반환한 행의 수, 시간 등을 나타냅니다. Planning time은 PostgreSQL이 실행 계획을 수립하는 데 걸린 시간입니다. Execution time은 쿼리를 실행하는데 걸린 시간을 의미합니다.
2. Query Execution Plan
쿼리 플랜은 다음과 같이 EXPLAIN을 사용해서 얻을 수 있습니다.
1
2
3
4
5
6
7
8
9
EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS, FORMAT JSON)
SELECT
zip,
ROW_NUMBER() OVER (ORDER BY price DESC) AS price_rank,
RANK() OVER (PARTITION BY type ORDER BY price DESC) AS type_price_rank
FROM
test
WHERE
city = 'SACRAMENTO';
- analyze 실제 실행 계획을 분석하고 실행 속도 등 정보
- costs 쿼리 실행에 소요되는 비용
- verbose 실행계획에 더 자세한 정보, 어떤 인덱스, 어떤 테이블 스캔
- buffers 버퍼정보, 각 단계별 버퍼
- format json 실행계획을 json 반환하기 위해

이렇게 시각화된 자료로 얻을 수 있습니다. 그림으로 실행계획 순으로 그림으로 볼 수 있고 아래 테이블에서는 실행 계획을 의미합니다.
- exclusive 특정 단계에서 소요된 시간
- inclusive 해당 단계 + 하위 계획 단계를 포함한 총 시간
- rowx 는 각 단계에서 예상되는 행의 수
- actual은 실제 단계에서 반환된 행의 수
- plan은 실행 계획 단계의 실행 계획 방법과 관련된 정보
앞서 보여드린 쿼리 플랜을 다시 보겠습니다. WindowAgg(윈도우 어그리게잇)으로 비용, 반환한 행의 수, 시간 등을 나타냅니다. 첫 번째 괄호 부분은 예상 계획에 따른 것으로 옵티마이저가 예상하는 실행 계획의 시작 비용과 종료 비용을 표기한 cost, rows 예상 행의 수, width 결과 집합의 폭, 각 행의 폭이 116바이트라는 것을 의미합니다. 그 다음 괄호는 실제 실행시간과 실제 처리된 행의 수, 루프 수를 나타냅니다. planning time은 PostgreSQL이 실행 계획을 수립하는 데 걸린 시간입니다. execution time은 쿼리를 실행하는데 걸린 시간을 의미합니다.
쿼리 실행계획을 읽을 때에는 안쪽에서 바깥쪽으로 그리고 같은 들여쓰기로 표시된 경우는 위에서 아래 방향으로 읽습니다.
3. Query Tuning Approaches
쿼리 튜닝에 대한 발표를 하기 전에 정말 다양한 자료를 찾아봤는데 데이터베이스별, 난이도별 다양한 접근법과 이야기들이 있어 애초에 모든 내용은 담을 수 없겠다는 생각이 들었습니다. 그래서 가장 핵심적인 부분 몇 가지만 소개하는 걸로 발표주제를 잡았고 다양한 연령의 사람들이 많이 참여하는 행사인만큼 지루하지 않을 수 있는 정도의 내용을 담았습니다. 발표자료를 다 담기는 어렵고 핵심정리 내용을 4가지로 담아서 이 부분만 정리해보려고 합니다.
Where 조건절의 순서와 Like로 찾는 범위를 줄이자.
데이터가 많은 경우에 where 조건절의 순서로 인해 성능차이가 나는 경우가 있었습니다. like 조건에 % 와일드 카드를 양쪽에 두어 찾는 경우가 있는데 이럴 때는 인덱스 사용도 할 수 없고, 전체 테이블 조회로 시간이 소모됩니다. 하지만 앞에 문자열을 두게 되면 시작부가 고정되어 있어 인덱스 활용이 가능해집니다.
인덱스 유형을 알고 필요한 컬럼에 인덱스를 설정하자.
인덱스를 만들기 전에 진짜 그게 최선인가 고민해볼 필요가 있습니다. 불필요한 인덱스로 오히려 다른 쿼리 성능을 떨어트리는 방식이 될 수도 있기 때문입니다. 그럼에도 인덱스가 필요한 경우에는 자주 조회되고 쓰기가 자주 일어나지 않는 컬럼, 값 중복이 적은 컬럼, 연산 기능에 사용될 가능성이 높은 컬럼에 인덱스를 거는 것이 좋습니다. 추가하는 경우는 반드시 history를 사용해서 인덱스 사용시에 다른 쿼리와의 연관성도 살필 필요가 있습니다.
Postgresql에서는 지정없이 만들게 되면 기본적으로 b-tree 인덱스로 만들어집니다. BETWEEN, >, <, >=, <=와 같은 연산자를 사용하는 쿼리에 적합한 인덱스로 정렬된 순서로 데이터를 저장하기 때문에 ORDER BY 쿼리나 GROUP BY 쿼리에서도 유리합니다. 그 외에는 Hash 인덱스, GiST(Generalized Search Tree) 인덱스, GIN(Generalized Inverted Index) 인덱스, BRIN(Block Range Index) 인덱스 등이 있습니다.
결과 데이터 양에 따라 스캔 방식별 효율성이 달라진다.
스캔은 데이터를 조회해올 때 사용되는 방법으로 실행계획에서 가장 아래 노드에 있습니다. 가장 처음 시작된다고 할 수 있습니다. Bitmap Index Scan, TID Scan 방식들이 있지만 여기서 헷갈릴 수 있는 인덱스 스캔 방식에 대해 설명하겠습니다.
Index Scan:
인덱스를 사용해 조건에 맞는 키를 찾고, 해당 키로 테이블 행에 접근합니다. 범위 검색이나 정렬된 데이터에 적합합니다. 실제 테이블 데이터에 접근해야 하므로 비교적 느릴 수 있습니다.
Index-Only Scan:
인덱스가 쿼리에 필요한 모든 데이터를 포함할 때 사용됩니다. 실제 테이블에 접근할 필요 없이 인덱스에서 데이터를 얻습니다. 매우 빠른 성능을 제공합니다.
Bitmap Index Scan:
여러 조건이나 인덱스를 사용하는 쿼리에 적합합니다. 조건에 맞는 행을 비트맵으로 표시한 후, 해당 행들을 테이블에서 검색합니다. 중간 규모 이상의 결과 집합에 효율적입니다.
결과값이 작다면 Nested Join이 되도록 인덱스 컬럼을 만들자!
Nested Loop Join (중첩 루프 조인)은 가장 간단하고 일반적인 조인 방법입니다. 외부 테이블(outer relation)을 순차적으로 스캔하면서, 각 행에 대해 내부 테이블(inner relation)을 매칭하는 행을 찾습니다. 외부 테이블이 작은 경우에 효율적이며, OLTP 워크로드에서 자주 사용됩니다. 그리고 내부 테이블의 조인 키에 인덱스가 있으면 중첩 루프 조인의 속도가 상당히 빨라질 수 있습니다.