스프링 부트와 JPA 실무 완전 정복 로드맵
김영한의 스프링 부트와 JPA 실무 완전 정복 로드맵 내용을 기반으로 Spring boot + JPA + Querydsl 학습 내용을 정리한 자료입니다.
연관관계 매핑
다중성, 단방향VS양방향, 연관관계의 주인
JPA를 처음 배우는 사람들이 가장 헷갈리고 어렵게 느낄 수 있는 부분일 것 같다고 생각합니다. 이하 내용은 김영한님 인프런 로드맵 학습내용을 기반으로 연관관계 매핑에 대해 정리했습니다.
연관관계란 데이터베이스에서 외래키로 RDB 관계를 설정하는 것처럼 객체지향 설계에서 객체를 참조하는 방식을 이야기합니다. 연관이 있는 관계, 예를 들면, 어떤 반에 속하는 학생이 여러 명이라면 그 반과 학생들은 1:N 매핑으로 설명할 수 있습니다. 이렇게 JPA에서는 연관관계를 외래키가 없이 객체의 참조 방식으로 연관을 지을 수 있는 방법을 제공합니다.
연관관계 매핑시 고려사항
연관관계는 크게 단방향과 양방향 매핑으로 나뉩니다. 단방향은 말 그래도 한 쪽에서 다른 관계를 참조하는 것이고, 양방향은 양쪽에서 참조가 가능합니다. 연관관계에서는 주인을 정하고 주인이 아닌 방향에서는 단순 읽기를 위해 주로 참조를 걸지만, 실무에서는 양쪽의 데이터를 간편하게 가지고 오기 위해 양방향 매핑이 많이 사용됩니다.
연관관계의 주인은 외래키가 있는 테이블(N)과 매핑되는 entity에 설정하는 것을 권장됩니다. 그 반대쪽에는 mappedBy로 관계를 알 수 있는 변수명을 매핑해주어야 합니다. 외래키가 있는 곳을 주인으로 정하는 이유는 데이터베이스 작업을 할 때, 주인인 entity를 중심으로 JPA는 작업을 수행합니다. 외래키 값이 같이 업데이트하면서 관리와 유지보수가 더 편하기 때문입니다.
연관관계를 사용할 때는 순수 객체 상태를 고려해서 항상 양쪽에 값을 설정하는 것이 좋습니다. 따라서 한 쪽 entity의 setter 메서드 대신 연관관계의 반대에도 자동으로 set이 될 수 있도록 알아보기 쉬운 메서드를 따로 지정해주는 것이 좋습니다. 그래야 양쪽 다 값을 잊지 않고 설정하기에 편리합니다.
연관관계 종류와 전략
다대일 [N:1]
매핑으로는 다대일 양방향으로 사용하는 것을 추천합니다. 맨 처음 예시로 들었던 학생과 반에 대한 연관관계 entity를 코드로 작성했습니다. 아래 코드에서는 다대일 양방향 매핑이 된 상태입니다.
1
2
3
4
// 학생 entity
@ManyToOne
@JoinColumn(name="TEAM_ID")
private Team team;
@JoinColumn에 대하여
외래키를 매핑할 때 사용합니다. @JoinColumn을 쓰지 않으면 @JoinTable 전략으로 동작하기 때문에 불필요한 테이블이 하나 더 생기고 관리하기에 비효율적입니다.
일대다 [1:N]
다대일과 달리 mappedBy 속성이 있습니다. 여기서 연결해주는 대상은 일대다와 묶인 상대 즉, 여기서는 @ManyToOne으로 설정한 entity 속성의 변수명을 작성해주면 됩니다.
1
2
3
4
// 팀 entity
@OneToMany(mappedBy="student")
@JoinColumn(name="STUDENT_ID")
private List<Student> students = new ArrayList<>();
일대일 [1:1]
일대일 양방향은 다대일 양방향 매핑과 유사합니다. 하지만 일대일이기 때문에 어느 방향에 외래키를 넣어도 되지만, 향후 기능 추가와 DBA와의 협업으로 어떻게 주인을 설정할지 고민해봐야 합니다. 일반적으로 전통적인 데이터베이스 설계와 동일하게 대상테이블에 외래 키를 넣는 방식으로 하면, 나중에 일대다 매핑으로 변경시에도 테이블 구조가 유지된다는 장점이 있습니다. 하지만, 프록시 기능의 한계로 지연로딩으로 설정해도 항상 즉시로딩된다는 단점이 있습니다.
1
2
3
4
5
6
7
8
9
// 팀 entity
@OneToOne(mappedBy="student")
@JoinColumn(name="STUDENT_ID")
private Student student;
// 학생 entity
@OneToOne
@JoinColumn(name="TEAM_ID")
private Team team;
다대다 [N:M]
관계형 데이터베이스에서는 표현할 수 없는 방식으로 실무에서 사용하지 않습니다. 중간 테이블을 만들어 일대다 또는 다대일 관계로 만들어야 합니다. 하지만 중간테이블을 따로 관리하는 것보다 차라리 중간테이블을 entity로 승격해서 관리하는 것을 권장됩니다.
1
2
3
4
5
6
@ManyToMany(fetch=LAZY)
@JoinTable(name="CATEGORY_ITEM",
joinColumn=@JoinColumn(name="CATEGORY_ID"),
inverseJoinColumns=@JoinColumn(name="ITEM_ID")
)
private List<Item> items = new ArrayList<>();
즉시로딩과 지연로딩
연관관계 속성에서 fetch 전략을 fetchType.LAZY으로 지연로딩으로 선택하거나, fetchType.EAGER으로 즉시로딩을 설정할 수 있습니다. 하지만 즉시로딩을 할 경우 성능이 나빠지거나 예상치 못한 쿼리들이 발생하기 때문에 사용을 피하는 것이 좋습니다. @ManyToOne, @OneToOne은 기본값이 즉시로딩이므로 @ManyToOne(fetch=fetchType.LAZY)와 같이 반드시 지연로딩 설정해서 위험을 방지해야 합니다.
대신 JPQL fetch 조인이나 엔티티 그래프 기능을 사용해서 이 문제를 해결할 수 있습니다.
영속성 전이 CASCADE
특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들고 싶을 때 사용됩니다. 연관관계 매핑과는 아무런 관련이 없지만 cascade=CascadeType.PERSIST와 같이 어노테이션 전략으로 작성되기 때문에 여기에 분류했습니다. CASECADE 종류에는 ALL, PERSIST, REMOVE, MERGE, REFRESH, DETACH가 있습니다. 영속성 전이가 다른 부모와 연관이 없는 자식 엔티티에만 적용하는 것이 좋습니다.
고아객체
고아객체는 부모 엔티티와 관계가 끊어진 자식 엔티티를 말합니다. orphanRemoval = true와 같이 사용되는데 설정 후 부모 엔티티의 자식 리스트에서 하나를 삭제하면, 그 자식 엔티티와는 관계를 맺지 않습니다. 특정 엔티티가 개인 소유할 때만 사용하는 것이 좋습니다. CascadeType.REMOVE와 같이 부모 엔티티가 삭제되는 경우, 자식 엔티티도 같이 제거됩니다.
CASCADE와 고아객체를 모두 사용하면 자식 엔티티의 생명주기를 모두 관리할 수 있습니다.(DDD의 Aggregate Root 개념 구현시 유용)
상속관계 매핑
@Inheritance
상속관계가 있는 entity를 만들때, JPA는 extends된 엔티티를 모두 하나의 단일 테이블로 하는 전략을 기본으로 합니다. 하지만 다른 방식으로 상속매핑을 처리하고 싶은 경우에는 @Inheritance의 다른 전략을 사용해주면 됩니다.
1
2
3
@Inheritance(strategy=InherianceType.JOINED) // 조인전략
@Inheritance(strategy=InherianceType.SINGLE_TABLE) // 단일 테이블 전략
@Inheritance(strategy=InherianceType.TABLE_PER_CLASS) // 구현 클래스마다 테이블 전략
단일 테이블 전략에서는 상속된 테이블의 모든 컬럼을 가지고 있기 때문에 null을 허용해야 하는 부분이 많다는 단점이 있습니다. 테이블 간의 관계나 확장을 고려해서 중요한 설계가 필요한 경우에는 JOIN 전략을 사용하는 것이 좋습니다. TABLE_PER_CLASS 전략은 상속 매핑을 파악하기에 좋지 않기 때문에 사용하지 않는 것이 좋습니다.
@DiscriminatorColumn
부모 클래스에서 구분을 위해서 사용합니다. 단일 테이블 전략에서는 자동으로 @DiscriminatorColumn를 사용하지 않아도 구분이 되는 컬럼으로 DTYPE이 생성됩니다. 하지만 JOIN 전략에서는 DTYPE이 생성되지 않고 하위 테이블에 제약조건이 생성되기 때문에 별도의 구분용 컬럼이 필요하지 않기 때문입니다.
@DiscriminatorValue
자식 클래스에서 부모클래스 @DiscriminatorColumn용 컬럼에 들어갈 값으로 상속관계의 매핑 테이블을 구분하기 위해 사용합니다. 자식클래스에 DTYPE에 들어갈 값을 지정할 수 있습니다.
@MappedSupperclass
공통 매핑 속성정보를 사용하고 싶을 때를 사용합니다. 모든 테이블에 동일하게 누가 수정하고, 수정일시가 언제인지에 대한 정보가 필요하다고 한다면, BaseEntity를 만들어 매핑정보만 제공할 수 있도록 합니다. 이 class는 entity는 아니고 단순히 공통 속성을 부여하기 위한 것으로 상속관계 테이블이 생성되는 개념이 아닙니다.
코드로 살펴보기
상속 관계의 부모클래스에 @Inheritance와 @DiscriminatorColumn를 지정해서 자식 클래스가 상속될 수 있도록 합니다. 이 때, 자식 클래스에는 @DiscriminatorValue로 DTYPE에 들어갈 값을 정해주고, extends를 표기해 상속임을 나타냅니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "dtype")
@Getter
@Setter
@Table(name = "ITEM")
public class Item {
@Id @GeneratedValue
@Column(name="item_id")
private Long id;
private String name;
private int price;
private int stockQuantity;
@ManyToMany(mappedBy = "items")
private List<Category> categories = new ArrayList<>();
}
@Entity
@DiscriminatorValue(value = "M")
@Getter
@Setter
public class Movie extends Item{
private String director;
private String actor;
}
프록시와 연관관계
실제 클래스를 상속받아서 만들어진 것으로 프록시를 이용해서 조회하는 기능인 em.getReference()를 사용하는 경우 프록시 객체를 조회하며, 영속성 컨텍스트에 이미 entity가 있다면 실제 entity를 반환합니다. 참고로, em.find()는 실제 객체를 조회합니다.
프록시 객체와 영속성 컨텍스트
여기서 프록시 객체란 JPA에서 실제 데이터베이스 조회를 지연할 수 있게 하는 가짜 객체입니다. 프록시 객체는 실제 객체를 target 변수로 가지고 있고, 조회를 하면 그 참조값으로 영속성 컨텍스트에게 초기화 요청을 보내서 실제 객체를 조회합니다. 한 번 조회된 이후에는 target 참조가 걸리기 때문에 두 번째부터는 초기화 요청을 하지 않습니다.
정리하면, 프록시 객체를 초기화 할 때, 프록시 객체가 실제 엔티티로 바뀌는 것은 아니며, 초기화되면 프록시 객체를 통해서 실제 엔티티에 접근 가능이 가능합니다.
코드로 살펴보기
여기서 m1, m2는 모두 같은 프록시 객체에서 조회해 온 것을 의미합니다. 따라서 여기서는 동등비교(==)를 해도 true가 나오는 것을 알 수 있습니다. 프록시 객체 타입을 비교할 때는 instanceOf를 사용해야 합니다.
1
2
3
Member m1 = em.getReference(Member.class, "m1Id");
Member m2 = em.getReference(Member.class, "m1Id");
System.out.println(m1 == m2); // true
처음에는 프록시 객체를 생성하고, getName() 조회를 하는 순간, 영속성 컨텍스트에 초기화 요청으로 실제 객체를 참조하게 됩니다. 이후 같은 객체를 선언하는 m2에는 실제 객체를 바로 조회하게 됩니다. 이미 영속성 컨텍스트에서 관리하는 객체이기 때문입니다.
1
2
3
Member m1 = em.getReference(Member.class, "m1Id"); // 프록시 객체
m1.getName(); // 초기화 요청
Member m2 = em.getReference(Member.class, "m1Id"); // 실제 객체
자바 ORM 표준 JPA 프로그래밍 - 기본편
Proxy Objects and Eager & Lazy Fetch Types in Hibernate
[JPA] 영속성 전이, 고아 객체 (cascade 범위)
OSIV
스프링부트에서는 Open Session In View를 기본값으로 하고 있기 때문에 영속성 컨텍스트를 뷰 렌더링이 끝나는 시점까지 개방한 상태로 유지합니다.
준영속 상태에서는 프록시를 초기화하면 hibernate는 org.hibernate.LazyInitializationException 예외가 발생할 수 있습니다. 이 문제는 스프링 @Transaction을 사용하는 과정에서 발생하는데, 서비스단에서 받은 entity를 컨트롤러에서 mapper로 DTO 처리하는 과정에서 흔히 볼 수 있는 문제입니다. @Transaction이 명시된 서비스단 메서드가 종료되면, 영속성 컨텍스트에서 그 객체를 관리하지 않기 때문에 실제 객체로 mapper 처리를 제대로 하지 못하는 문제가 발생하기 때문입니다.
실전! 스프링 부트와 JPA 활용2 - API 개발과 성능 최적화
데이터 타입
JPA 타입은 엔티티 타입(@Entity 식별자로 인식)과 값 타입(식별자 없이 값만 있는 추적 불가능한 타입)으로 분류할 수 있습니다. 값 타입은 추적이 불가능하기 때문에 절대 공유되면 안됩니다. 즉, Interger, String 같은 공유가능한 주소값만 넘어가기 때문에 변경이 불가능합니다. JPA에서 값 타입의 종류로는 기본값 타입, 임베디드 타입, 컬렉션 값 타입이 있습니다.
값 타입을 원시타입인 경우는 동일성 비교로 ==를 사용하면 되지만, 그 외에 임베디드 타입과 같은 값을 비교할 때는 equals()를 사용해서 동등성 비교를 해야 합니다.
immutable한 객체에 대해 더 자세히 알아보자!
Java에서 Integer나 String은 immutable한 객체입니다. 이러한 객체들은 공유 가능한 주소값만 넘어가기 때문에 변경이 불가능합니다. 예를 들어, Integer a = 5; 와 Integer b = a; 라는 코드가 있다면, a와 b는 같은 주소값을 공유하게 됩니다. 따라서 a나 b 중 하나를 변경하면 다른 하나도 함께 변경되는 것이 아니라, 새로운 객체가 생성됩니다. JPA의 엔티티 일부로 사용될 수 있는 값 타입입니다.
임베디드 타입(복합 값 타입)
임베디드 타입도 엔티티 타입이 아니기 때문에 추적이 불가능합니다. Member 엔티티에서 Address 객체를 값 타입처럼 사용할 수 있습니다. @Embedded으로 임베디드 타입의 값임을 명시하고, @Embeddable로 클래스가 임베디드 타입임을 명시합니다. 현업에서는 주소나 연락처와 같이 엔티티에서 자주 사용되는 값들을 임베디드 타입으로 정의하여 사용합니다. 예를 들어, 회원(Member) 엔티티에서는 회원의 이름, 나이, 주소, 연락처 등이 자주 사용되는데, 이러한 값들을 임베디드 타입으로 정의하여 Member 엔티티에서 사용할 수 있습니다. 값 타입을 별도의 테이블로 분리하여 저장하면 조인이 발생하므로 성능이 저하될 수 있습니다. 이러한 경우에도 임베디드 타입을 사용하면 Member 테이블과 함께 저장되므로 성능상 이점이 있습니다. 또한, 임베디드 타입을 사용하면 코드의 가독성이 좋아지고, 객체를 다루는 코드가 간결해집니다. 따라서 현업에서도 임베디드 타입을 자주 사용하는데, 이는 객체지향적인 설계를 할 수 있게 해주기 때문입니다.
아래 코드로 보면, Address 객체를 따로 테이블로 만들지 않고 Member 테이블과 함께 개개의 컬럼으로 생성되어 저장됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
@Entity
public class Member {
@Id
private Long id;
private String name;
@Embedded
private Address address;
// ...
}
@Embeddable
public class Address {
private String city;
private String street;
private String zipcode;
// ...
}
임베디드 타입에서 @Embeddable 객체를 공유 참조하는 경우, 그 객체를 사용하는 entity들에서 모두 변경이 발생하는 문제가 발생할 수 있습니다. 이 경우 추적이 어렵기 때문에 반드시 공유 참조를 하려는 대상을 불변객체로 생성해야 합니다. setter 메서드를 사용하지 않아야 하며, 변경할 필요가 있는 경우에는 새로운 객체를 다시 만들어서 값을 수정하는 방식이 안전합니다.
[불변객체로 설정하지 않은 경우의 문제점]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Address address = new Address("city", "street", "10000");
Member member1 = new Member();
member1.setName("member1");
member1.setHomeAddress(address);
Member member2 = new Member();
member2.setName("member2");
member2.setHomeAddress(address);
em.persist(member1);
em.persist(member2);
address.setCity("seoul");
// member1과 member2 모두 address의 city가 'seoul'로 변경됩니다.
[불변객체로 설정했을 때의 임베디드 타입의 값 변경]
1
2
3
4
5
6
7
8
9
10
Address address = new Address("city", "street", "10000");
Member member1 = new Member();
member1.setName("member1");
member1.setHomeAddress(address);
em.persist(member1);
// 수정이 필요한 경우
Address newAddress = new Address("seoul", address.getStreet(), address.getZipcode());
member1.setHomeAddress(newAddress);
BaseEntity를 사용하면 되지 않을까?
여기서 이런 의문이 들었습니다. 공통 속성이라면 BaseEntity로 관리하는 방법도 있는데, 컬럼에 대한 임베디드 값 타입으로 설정하는게 어떤 부분에서 크게 다른지 생각해봤습니다.
@Embedded와 @Embeddable을 사용하면 하나의 엔티티에서 여러 개의 값을 그룹화할 수 있습니다. 이렇게 그룹화된 값은 다른 엔티티에서도 재사용할 수 있습니다. 또한, 값 타입을 별도의 테이블로 분리하여 관리할 수 있기 때문에 데이터 일관성과 중복성을 줄일 수 있습니다.
개념적인 부분에서도 BaseEntity는 상속을 하는 개념으로 공통 컬럼들을 정의합니다. 하지만 @Embedded를 이용하는건 주소라는 컬럼 내에 우편번호, 기본주소, 상세주소와 같은 하나의 그룹화된 속성들을 지정한다는 점에서 차이가 있습니다. 결론적으로 여러 엔티티의 공통 속성을 묶에서 관리하기 위해서는 상속 개념을 이용하는 것이 바람직하고, 하나의 속성을 세부 속성들을 그룹화해서 사용하기 좋은 것은 임베디드 값 타입을 사용하는 것이 적절합니다.
컬렉션 값 타입
값 타입을 하나 이상 저장할 때 사용되며, 자바의 컬렉션을 사용합니다. 값 타입 컬렉션은 CASCADE를 기본값으로 갖고 있으며, 영속성 전에(Cascade) + 고아 객체 제거 기능을 필수로 가진다고 볼 수 있습니다. 만약 값 타입 컬렉션에 변경 사항이 발생하면, 주인 엔티티와 연관된 모든 데이터를 삭제하고, 값 타입 컬렉션에 있는 현재 값을 모두 다시 저장합니다.
@ElementCollection을 사용해서 컬렉션 타입을 사용할 수 있는데, 자동으로 부모 id를 기본키로 갖는 테이블이 member_roles라는 테이블이 자동으로 생성됩니다. @CollectionTable으로 컬렉션 값 타입에 사용될 테이블 속성을 명시적으로 지정해 줄 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
@Entity
public class Member {
@Id
@GeneratedValue
@Column(name = "member_id")
@Setter
private Long id;
@Column
@ElementCollection
private List<String> roles = new ArrayList<>();
@ElementCollection
@CollectionTable(name="OPTIONS", joinColumns=@JoinColumn(name="MEMBER_ID"))
private List<String> options = new ArrayList<>();
}
컬렉션 값 타입은 지연로딩 전략을 사용하기 때문에 컬렉션 값 타입을 조회하는 등 필요한 순간에 쿼리가 생성됩니다.
1
2
Membmer member = em.find(Member.class, member.getId()); // member만 조회
member.getRols(); // 컬렉션 값 타입 조회
JPA 타입에 대해 이것만은 알고가자!####
- 임베디드 타입을 컬렉션 값 타입으로 함께 혼용 사용할 수 있습니다.
- 현업에서는 컬렉션 값 타입이 아주 간단한 영역이 아닌 경우,
일대다또는다대일연관관계로 변경해서 사용해 엔티티 추적을 용이하게 사용합니다. - 추적이 불가능한 임베디드나 컬렉션 값 타입을 사용할 경우 반드시
불변객체로 만들어서 사용해야 합니다.
자바 ORM 표준 JPA 프로그래밍 - 기본편
[JPA] 값 타입과 불변 객체 - 값 타입 (2)
[JPA] 값 타입 컬렉션 : @ElementCollection, @CollectionTable
[Spring JPA] @Embedded, @Embeddable
객체지향 쿼리 언어
JPQL, JPA Criteria, Query DSL, 네이티브 SQL, JDBC API를 사용하는 등 다양한 쿼리방법을 지원합니다.
영속성 컨텍스트 동기화가 필요한 경우
JPA와 함께 JDBC API나 MyBatis를 사용하는 경우에는 영속성 컨텍스트를 명시적으로 flush()해줘야 합니다. 왜냐하면, 아직 DB에 반영되지 않은 데이터를 JPA를 우회해서 조회하기 때문에 무결성 문제가 발생합니다. 따라서 우회 접근 전 반드시 영속성 컨텍스트 동기화 처리가 필요합니다.
JPQL
Java Persistence Query Language
JPA에서 사용하는 쿼리 언어로 엔티티 객체를 대상으로 쿼리를 작성합니다. SQL과 유사하지만 entity 객체를 대상으로 쿼리한다는 특징이 있습니다. JPQL은 SQL을 추상화해서 특정데이터베이스 SQL에 의존하지 않습니다.
TypedQuery는 반환타입이 명확한 경우에 사용되고, 명확하지 않은 경우는 그냥 Query로 작성합니다.
1
2
3
4
5
6
7
8
// 파라미터 이름을 이용한 바인딩
TypedQuery<User> query = entityManager.createQuery("SELECT u FROM User u WHERE u.age > :age ORDER BY u.name DESC", User.class);
query.setParameter("age", 20);
List<User> users = query.getResultList();
// 위치 기반 파라미터를 사용한 바인딩
Query<Member> query = entityManager.createQuery("SELECT m FROM Member m WHERE age=?1");
query.setParameter(1, 20);
프로젝션
프로젝션은 JPQL에서 SELECT절에서 어떤 데이터를 조회할 것인가를 말합니다. 조회하는 데이터 속성에 따라 객체 프로젝션, Embedded 프로젝션, 스칼라 프로젝션으로 구분됩니다.
1
SELECT m.name FROM Member m
페이징
쿼리를 생성할 때 결과 값의 처음 setFirstResult과 마지막 setMaxResults을 설정하고 페이징처리해서 List로 페이징 처리된 값을 가지고 올 수 있습니다.
1
2
3
4
5
List<Member> query = entityManager.createQuery("SELECT m FROM Member m WHERE age=:age")
.setFirstResult(0)
.setMaxResults(10)
.getResultList();
query.setParameter("age", 20);
조인
조인에는 내부조인, 외부조인, 세타조인이 있습니다. 세타조인은 연관관계 없는 두 테이블을 조인하고 싶을 때 사용합니다. 이 때 조인의 값은 FULL JOIN처럼 조인되고 거기서 조건절에 해당하는 값을 도출합니다.
서브쿼리
EXISTS, ALL, ANY, IN과 같은 기능을 제공합니다. 하이버네이트는 SELECT에서도 서브쿼리를 사용할 수 있도록 지원합니다. JPA 표준 스펙사항은 WHERE과 HAVING 절에서만 사용이 가능합니다. 하지만 FROM절에서 서브쿼리가 되지 않습니다.
ENUM 타입
패키지명을 포함해서 jpql.MemberType.ADMIN와 같이 대입하거나 파라미터 바인딩으로 조건절 추가가 가능합니다.
조건문
COALESCE를 사용하면 NULL이 아닌 것을 반환할 수 있습니다. SELECT COALESCE(m.name, '이름이 없다') FROM Member m와 같이 사용됩니다. 이름이 없는 경우는 ‘이름이 없다’로 출력됩니다.
NULLIF는 원하는 값인 경우는 NULL을 반환합니다. SELECT NULLIF(m.name, '홍길동') FROM Member m 여기서 이름이 홍길동일 경우 NULL을 반환합니다.
사용자 정의 함수
사용 전 사용하는 DB에 상속받고 등록해야 사용할 수 있습니다. JPQL로 MySQL의 사용자 정의 함수를 어떻게 사용하는지 알아보겠습니다. 먼저, MySQL에 사용자 정의함수를 등록하기 위해서는 다음과 같이 함수를 생성해줍니다.
CREATE FUNCTION '함수명' (
파라미터
) RETURNS 반환할 데이터타입
BEGIN
수행할 쿼리
RETURN 반환할 값
END
사용자 정의 함수는 사용하기 위해 com.example.MySqlFunctions 사용자 정의 함수가 포함된 패키지를 가지고 등록한 함수명과 파라미터를 넣어서 쿼리를 작성하면 됩니다.
1
2
3
4
5
TypedQuery<Employee> query = entityManager.createQuery(
"SELECT e FROM Employee e WHERE FUNCTION('com.example.MySqlFunctions.my_custom_function', e.salary) > 50000",
Employee.class
);
List<Employee> employees = query.getResultList();
경로표현식
경로표현식은 객체 그래프 탐색을 하기 위한 표현식입니다. 상태필드는 값을 저장하기 위한 필드를 말합니다. 연관필드는 단일 값 연관 필드로 묵시적 내부 조인이 발생하기 때문에 실무에서 문제가 발생할 수 있습니다. 되도록 명시적 조인으로 관리할 수 있는 쿼리로 만드는 것이 중요합니다.
1
SELECT o.customer.name, oi.quantity FROM Order o JOIN o.orderItems oi WHERE o.id = :orderId
패치 조인(fetch join)
JPQL에서 성능 최적화를 위해 제공하는 기능으로 JPA 즉시로딩처럼 객체 그래프를 SQL 한 번에 조회하는 개념입니다. 예를 들어 회원을 조회할 때, 연관된 팀을 같이 조회하고 싶은 경우 다음과 같이 쿼리를 작성할 수 있습니다.
1
select m from Member m join fetch m.team
- 패치조인의 대상인
team을 다 가져오는데, 별칭을 이용해서 원하는 값만 가지고 올 수가 없다는 단점이 있습니다. - 둘 이상의 컬렉션은
Cartesian Product을 만들어 내기 때문에 중복요소가 많이 발생할 수 있습니다. 이를 해결하기 위해서는LEFT JOIN FETCH로 패치 조인하는 방법으로 중복 데이터를 제거할 수 있습니다. - 컬렉션을 패치 조인하면
페이징 API를 사용할 수 없다는 단점이 있습니다. 모든 데이터를 가져오게 되므로, 이 데이터를 API에서 페이지 단위로 처리하기 어려울 수 있습니다.
다형성 쿼리
부모 클래스 타입으로 선언된 변수에 대해서도 자식 클래스의 데이터를 검색할 수 있습니다. 상속관계를 미리 @DiscriminatorColumn로 지정해 둔 상태이기 때문에 TYPE을 이용해서 특정 자식 타입에 접근할 수 있습니다.
1
SELECT a FROM Animal a WHERE TYPE(a) IN (Dog, Cat)
TREAT을 사용하면 부모타입을 특정 자식 타입으로 다루는 방법으로 사용이 가능합니다. 아래 코드에서 보면 Animal 별칭을 이용해서 Dog의 나이가 2살보다 많은 객체를 구할 수 있습니다.
1
SELECT a FROM Animal a WHERE TREAT(a as Dog).age > 2
Named 쿼리
정적쿼리로 미리 정의해두고 이름을 가지고 사용할 수 있는 쿼리입니다. 애플리케이션 로딩 시점에 초기화 후 재사용하고 로딩시점에 쿼리를 검증할 수 있다는 장점이 있습니다. 클래스 자체에 정의할 수도 있고 XML에 정의할 수도 있습니다.
1
2
3
4
5
6
7
8
9
@Entity
@NamedQuery(name = "Person.findByAge", query = "SELECT p FROM Person p WHERE p.age = :age")
public class Person {
@Id
private Long id;
private String name;
private int age;
// getters, setters, constructors
}
1
2
3
TypedQuery<Person> query = em.createNamedQuery("Person.findByAge", Person.class);
query.setParameter("age", 30);
List<Person> persons = query.getResultList();
벌크연산
벌크연산을 하게 되면 영속성 컨텍스트를 무시하고 데이터베이스에 직접 쿼리하기 때문에 벌크연산 후 영속성 컨텍스트를 초기화하는 것이 중요합니다.
1
2
3
4
Query query = em.createQuery("UPDATE Person p SET p.age = :newAge WHERE p.age < :oldAge");
query.setParameter("newAge", 40);
query.setParameter("oldAge", 30);
int updatedCount = query.executeUpdate();
Querydsl
Querydsl의 시작은 HQL의 도메인 타입과 문자열 타입안전성 이슈를 해결하는 것에서 비롯되어 지금은 JPA, JDO, JDBC, MongoDB 등 백엔드 지원을 위한 기술로 발전했습니다. 타입 안정성과 일관성이 Querydsl의 중요한 원리입니다.
QueryDSL은 다음과 같이 자바 코드로 쿼리를 작성하기 때문에 컴파일 타임에 오류를 확인할 수 있습니다. 따라서 런타임 오류가 발생할 가능성이 적습니다. 그리고 JPQL에 비해 가독성이 높고, 엔티티 별칭과 속성 등을 자동으로 생성해준다는 장점이 있습니다. 동적 쿼리 사용에도 적합합니다.
Querydsl 준비하기
시작하기 앞에 gradle 설정이 필요합니다. 기존에 spring web 프로젝트를 jpa를 이용해서 작업하고 있었던 것을 기준으로 추가해야할 내용은 아래와 같습니다. 이 코드는 Querydsl을 사용하기 위한 플러그인, 의존성 추가 라이브러리, 빌드를 위한 설정 내용을 담고 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// build.gradle
plugins {
id "com.ewerk.gradle.plugins.querydsl" version "1.0.10"
id 'java'
}
dependencies {
implementation 'com.querydsl:querydsl-jpa'
}
def querydslDir = "$buildDir/generated/querydsl"
querydsl {
jpa = true
querydslSourcesDir = querydslDir
}
sourceSets {
main.java.srcDir querydslDir
}
configurations {
querydsl.extendsFrom compileClasspath
}
compileQuerydsl {
options.annotationProcessorPath = configurations.querydsl
}
여기서 검증용 Q타입을 생성하기 위해서는 Gradle-Task-other-compileQuerydsl 실행 후 build-generated-querydsl 안에 생성된 것을 확인할 수 있다. 검증용 Q타입은 오리지널 타입의 public 속성을 담고 있는 쿼리용 타입으로 다음과 같이 사용됩니다.
Querydsl에서 사용되는 query를 보기 위해서는 application.yml 설정으로 확인이 가능합니다.
1
spring.jpa.properties.hibernate.use_sql_comments: true
Querydsl을 사용하는 방법
Q타입 객체를 사용하는 방법은 별칭을 사용하거나 기본 인스턴스를 사용하는 방법으로 나뉩니다. 하지만 위의 예시처럼 자동으로 Querydsl에서 제공하는 기본 인스턴스를 사용해도 됩니다.
1
QCustomer customer = new QCustomer("myCustomer");
여기서 Q타입 객체인 QCustomer는 기본으로 customer로 제공되며, 이후 Querydsl 안에서도 동일하게 사용이 가능합니다.
1
2
3
4
5
JPAQueryFactory queryFactory = new JPAQueryFactory(entityManager);
List<Customer> customers = queryFactory.selectFrom(customer)
.where(customer.age.gt(20))
.orderBy(customer.name.desc())
.fetch();
Querydsl 핵심문법 Querydsl은 JPQL과 마찬가지로 SQL 기능 대부분을 제공하고 있고, 편의를 위해 추가되는 기능들과 문법이 있는데, 기본적인 문법을 제외하고 몇 가지 문법만 기억을 하기 위해 정리해보았습니다.
검색 조건 쿼리####
1
2
3
4
5
6
7
8
customer.age.goe(30) // age >= 30
customer.age.gt(30) // age > 30
customer.age.loe(30) // age <= 30
customer.age.lt(30) // age < 30
customer.username.like("jane%") // like 검색
customer.username.contains("e") // like %member% 검색
customer.username.startswith("j") // like member% 검색
조인 쿼리
조인 쿼리에서는 innerJoin(), leftJoin() 등 모두 지원합니다. Querydsl 5.0부터는 fetchResult()와 fetchCount()가 deprecated 되었는데, 복잡한 다중쿼리에서 두 쿼리가 정상작동하지 않기 때문에 단순히 fetch() 처리 후 java size() 처리하거나 페이징 처리하는 것을 권장하고 있습니다. 다양한 조인 뒤에는 즉시로딩 처리를 위해 fetchJoin()을 추가해서 사용이 가능합니다.
1
2
3
4
// 연관관계 객체까지 모두 조인, 즉시로딩
selctFrom(customer).leftJoin(customer.order, order).fetchJoin().fetch()
// 즉시로딩 결과 값을 한 개 리턴
selctFrom(customer).leftJoin(customer.order, order).fetchJoin().fetchOne()
세타 조인은 연관관계가 없어도 데이터를 다 가지고 와서 조인을 하는 방식으로 카디널리티 곱을 반환합니다. 연관관계가 없는 경우에는 on절을 사용해 외부조인을 할 수 있습니다.
1
2
3
4
5
List<Tuple> result = queryFactory
.select(member,team)
.from(member)
.leftJoin(team).on(member.username.eq(team.name))
.fetch();
‘fetchJoin().fetch()’은 N+1 이슈에서 자유로울까?
JPA를 공부하면서 쿼리 성능 최적화를 위해 가장 대두되었던 부분이 N+1 이슈가 발생하는지에 대한 부분이었던 것 같습니다. Querydsl도 역시 fetch 조인을 제공하는데 문제가 없을까 궁금증이 생겼습니다.
fetchJoin()으로 즉시로딩 처리된 객체를 가지고 옵니다. 여기서 fetch()는 fetchJoin()으로 이미 로드된 엔티티를 추가적인 쿼리 없이 한 번에 조회하며, 이 때 중복된 엔티티를 가지고 오지 않기 때문에 N+1의 이슈를 해결할 수 있습니다.
추가로 JPA에서 N+1 이슈를 해결하기 위해 distinct는 조회 대상 객체의 중복을 제거하고 결과를 도출한다는 점에서 차이가 있습니다.
그렇다면 left outer join을 사용하는 경우 Querydsl을 어떻게 이용해야 할까요?
기본적으로 Parent 객체를 조회하고 Child 객체를 left join()하면, left outer join으로 Parent 객체를 기준으로 필요한 Child만 뽑아오게 됩니다. Projection을 사용해서 해결하거나 Result Aggregation으로 Querydsl 결과를 특정 키를 기준 삼아 그룹화할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
// Result Aggression을 이용한 경우
public List<Family> findFamily() {
Map<Parent, List<Child>> transform = queryFactory
.from(parent)
.leftJoin(parent.children, child)
.transform(groupBy(parent).as(list(child)));
return transform.entrySet().stream()
.map(entry -> new Family(entry.getKey().getName(), entry.getValue()))
.collect(Collectors.toList());
}
1
2
3
Map<Integer, List<Comment>> results = query.from(post, comment)
.where(comment.post.id.eq(post.id))
.transform(groupBy(post.id).as(list(comment)));
Projection
기존 JPA의 프로젝션보다 더 복잡한 컨트롤을 가능하게 합니다. 프로젝션 대상이 둘 이상인 경우는 Tuple이나 DTO 조회로 결과를 반환합니다. Querydsl은 프로퍼티 Setter, 필드 직접 접근, 생성자를 이용한 접근 방식을 제공합니다.
[프로퍼티 Setter를 이용하는 방식] 이 경우에는 dto에 각 프로퍼티에 대한 생성자가 필요하기 때문에 별도의 생성자를 생성하거나 @NoArgsContructor로 생성자를 만들어주어야 합니다.
1
2
3
4
5
6
List<MemberDto> result = queryFactory
.select(Projections.bean(MemberDto.class,
member.username,
member.age))
.from(member)
.fetch();
[필드 직접 접근 방식] 별도 생성자를 필요로 하지 않습니다. 별칭이 다른 경우는 .as()로 해결하고 서브쿼리는 ExpressionUtils.as(sourse, alias) 방식으로 해결합니다.
1
2
3
4
5
6
List<MemberDto> result = queryFactory
.select(Projections.fields(MemberDto.class,
member.username,
member.age))
.from(member)
.fetch();
[생성자 접근 방식] 값과 생성자 순서가 맞아야 하며, @AllArgsConstructor를 사용하고, setter가 필요하지 않습니다.
1
2
3
4
5
6
List<MemberDto> result = queryFactory
.select(Projections.constructor(MemberDto.class,
member.username,
member.age))
.from(member)
.fetch();
이 생성자 방식은 @QueryProjection을 지원합니다. @QueryProjection을 MemberDto에 사용하면, 아래와 같이 간결한 코드 표현이 가능합니다. 하지만 Querydsl에 대한 의존성이 dto에 생기기 때문에 유지보수에 적합하지 않을 수 있다는 단점이 있습니다.
1
2
3
4
List<MemberDto> result = queryFactory
.select(new QMemberDto(member.username, member.age))
.from(member)
.fetch();
BooleanExpression를 이용한 동적 쿼리
BooleanExpression를 이용하면 복합 조건을 작성해서 select, where 절에서 조건식으로 사용이 가능합니다. BooleanBuilder는 상태변경이 되고, null 조건은 무시되고, 다른 쿼리에서도 재활용이 가능하다는 장점이 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
private List<Member> searchMember(String usernameCond, Integer ageCond) {
return queryFactory
.selectFrom(member)
.where(usernameEq(usernameCond), ageEq(ageCond))
.fetch();
}
private BooleanExpression usernameEq(String usernameCond) {
return usernameCond != null ? member.username.eq(usernameCond) : null;
}
private BooleanExpression ageEq(Integer ageCond) {
return ageCond != null ? member.age.eq(ageCond) : null;
}
수정, 삭제 벌크연산
수정과 삭제를 하는 벌크연산은 영속성 컨텍스트 엔티티를 무시하고 바로 DB에 execute() 처리를 하기 때문에 영속성 컨텍스트를 초기화하는 것이 좋습니다.
1
2
3
4
5
6
7
long count = queryFactory
.delete(member)
.where(member.age.gt(18))
.execute();
em.flush();
em.clear();
우아한 형제들의 Querydsl 사용법
extends / implements 사용하지 않기
매 repository마다 JpaRepository를 상속받지 않고, JPAQueryFactory을 Bean으로 등록해서 사용합니다.
1
2
3
4
5
6
7
8
9
10
@Configuration
public class QuerydslConfiguration {
@Autowired
EntityManager em;
@Bean
public JPAQueryFactory jpaQueryFactory() {
return new JPAQueryFactory(em);
}
}
1
2
3
4
5
@Repository
@RequiredArgsConstructor
public class MemberRepositoryCustom {
private final JpaQueryFactory queryFactory; // 물론 이를 위해서는 빈으로 등록을 해줘야 한다.
}
동적 쿼리는 BooleanExpression 사용하기
BooleanExpression를 사용하면, null 값을 무시하고 단일 조건을 나타내는 인터페이스로 조합해 복잡한 동적쿼리를 만들 수 있습니다. BooleanBuilder는 BooleanExpression들을 모아서 사용할 수 있게 해줍니다. 상황에 따라 다르겠지만 통상 BooleanBuilder를 사용하는 경우, 여러 표현식을 가지고 조립하기 때문에 한 눈에 파악하는 것이 어렵습니다. 그리고 중복되는 조건식을 재활용하기에 BooleanExpression으로 메서드화하는 것이 유리합니다.
exist 메소드 사용하지 않기
count 쿼리로 동작하기 때문에 전체 다 조회하는 경우 성능이 떨어질 수 있습니다. 그리고 자체적으로 매 실행시 서브 쿼리를 생성하기 때문에 개발자가 직접 최적화하기 어렵습니다. 대신 join을 이용하는 것이 성능을 최적화할 수 있습니다.
Cross Join 피하기
조인을 명시하지 않는 묵시적 조인은 크로스 조인을 하게 되므로 성능이 떨어질 수 있습니다. 따라서 명시적 조인으로 불필요한 조회를 줄어야 합니다.
조회할땐 Entity 보다는 DTO를 우선적으로 가져오기, Select 칼럼에 Entity는 자제하기
Entity 자체를 가지고 오는 것은 영속성 컨텍스트의 1차 캐시 기능을 사용하고 불필요한 컬럼을 조회하게 됩니다. 그리고 OneToOne N+1 쿼리 발생하는 문제가 있습니다. 따라서 필요한 속성만을 DTO로 받아 리턴하는 것이 바람직합니다.
특히나 distinct를 사용하는 경우는 모든 row를 확인하기 때문에 반드시 필요한 컬럼만을 조회하는 것이 바람직합니다.
Group By 최적화하기
Querydsl은 MySQL과 달리 OrderByNull을 제공하고 있지 않습니다. 그리고 인덱스가 없다면 자동적으로 실행되는 정렬 알고리즘 Filesort이 동작하게 됩니다.
1
2
3
4
5
6
public class OrderByNull extends OrderSpecifier {
public static final OrderByNull DEFAULT = new OrderByNull();
private OrderByNull(){
super(Order.ASC, NullExpression.DEFAULT, NullHandling.Default);
}
}
Querydsl 에서 커버링 인덱스 사용하기
인덱스 검색으로 빠르게 처리하고 걸러진 항목에 대해서만 데이터 블록에 접근하기 때문에 성능의 이점을 얻게 됩니다. 하지만 인덱스가 많아질 수 있다는 단점이 있습니다.
페이징 성능 개선을 위해 No Offset 사용하기
데이터가 많아지면 offset+limit를 사용한 데이터 조회시 성능상 좋지 않기 때문에 No Offset을 사용해서 시작 지점을 인덱스로 찾아 읽는 것이 좋습니다.
일괄 Update 최적화하기
일괄 Update를 할 때는 Cache Eviction 처리를 해주어야 합니다. 영속성 컨텍스트의 Dirty Checking을 사용하면 오히려 많은 쿼리가 발생하고 성능상 단점이 될 수 있음으로 일괄 Update를 하는 것이 좋습니다.
JPA로 Bulk Insert는 자제하기
JPA 에는 auto_increment일때 insert 합치기가 적용되지 않으므로 이 기능이 필요하다면 JdbcTemplate 를 사용하면 됩니다.
Querydsl Doc
Querydsl GitHub
실전! Querydsl
자바 ORM 표준 JPA 프로그래밍 - 기본편
10장 객체지향 쿼리언어
JPQL DOC
Querydsl 에서 OneToMany 관계에서 Left Outer Join 이 필요할 경우
JPAQuery.fetchResults() is deprecated, how should I replace it?
[우아콘2020] 수십억건에서 QUERYDSL 사용하기
1. 커버링 인덱스 (기본 지식 / WHERE / GROUP BY)
Hibernate
JPA 구현체는 Hibernate 외에도 EclipseLink, OpenJPA, DataNucleus 등이 있습니다. 그 중에서도 가장 많이 사용되는 Hibernate에 대해 알아보려고 합니다. Hibernate는 자바 언어를 위한 객체 관계 매칭 프레임워크입니다. 실제 Spring 프로젝트에서 JPA를 사용하는 경우 Hibernate가 라이브러리가 포함되어 있는 것을 볼 수 있습니다.
Hibernate는 JPA 구현으로 SessionFactory, Session, Transaction으로 상속받고 각각의 Impl을 구현하고 있습니다. JDBC API를 사용하지 않고, Hibernate에서 제공하는 메서드만으로도 SQL을 대체할 수 있다는 장점이 있습니다. 따라서 비즈니스 로직에 집중할 수 있게 되고, 객체지향적 개발이 가능하게 합니다.
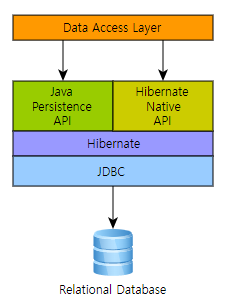
Hibernate ORM 5.4.33.Final User Guide
[JPA] JPA와 Hibernate 그리고 Spring Data JPA