DeadLock과 Redis 대기열
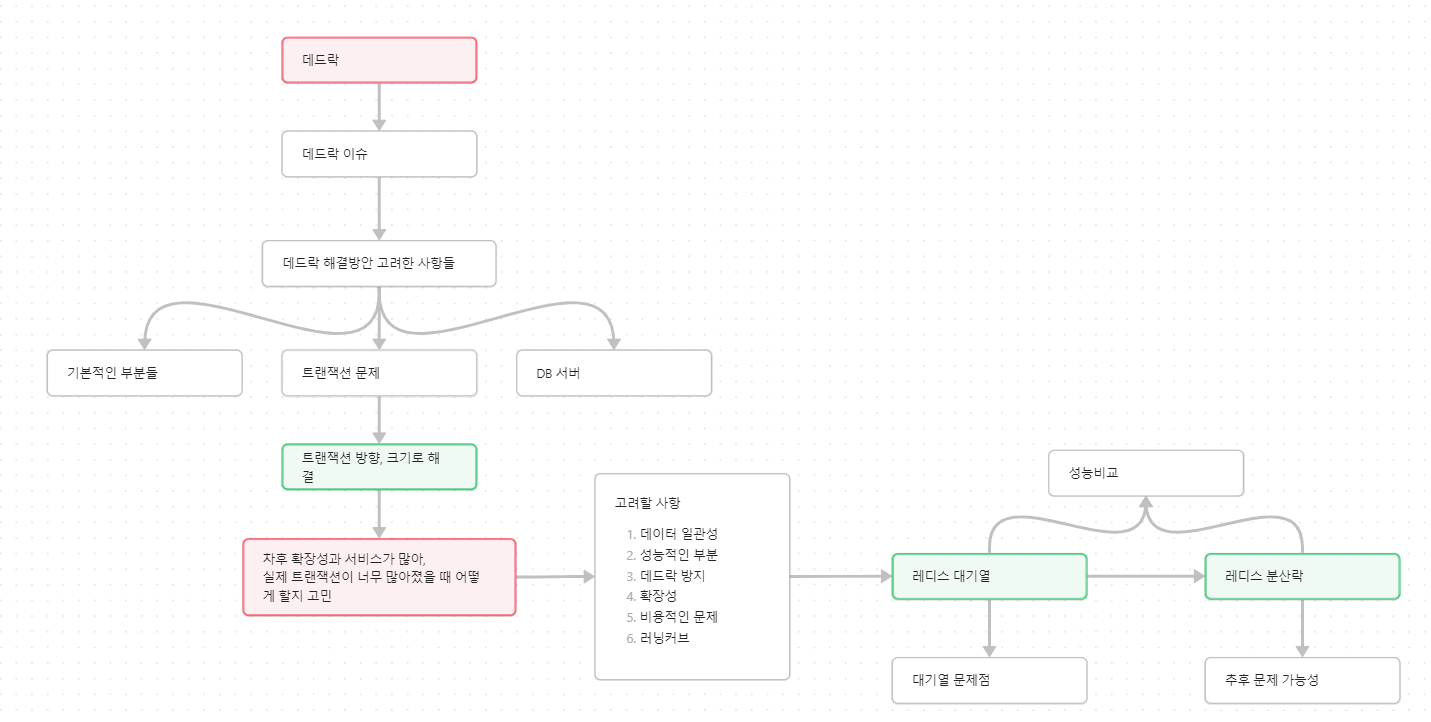
Flow Map
발표내용 설명에 앞서 이 포스팅은 발표 내용 중 일부만을 정리한 내용으로 포스팅만으로는 흐름 전달이 어려울 수 있다고 생각했습니다. 그래서 실제 발표를 준비하면서 만든 flow map 통해 어떻게 내용을 정리했는지 그리고 전반적인 순서들에 대해 먼저 이야기해보고자 합니다.
주 내용은 실제 경험한 deadlock 이슈 그리고 그걸 해결하기 위한 방법이 어떤 것들이 있는지에 대해 담았습니다. 이후에는 그 중에서 redis 대기열과 분산락을 이용해 순차 접근이 가능하도록 하는 과정을 설명했습니다.
핵심 해결과정 설명 전, 이해를 위해 redis에 대한 설명을 추가했습니다. 그리고 마지막으로 redis 대기열과 분산락 jmeter 성능비교 및 더 많은 트래픽을 견디기 위한 방법들에 대한 이야기를 담았습니다.
Deadlock에 대하여
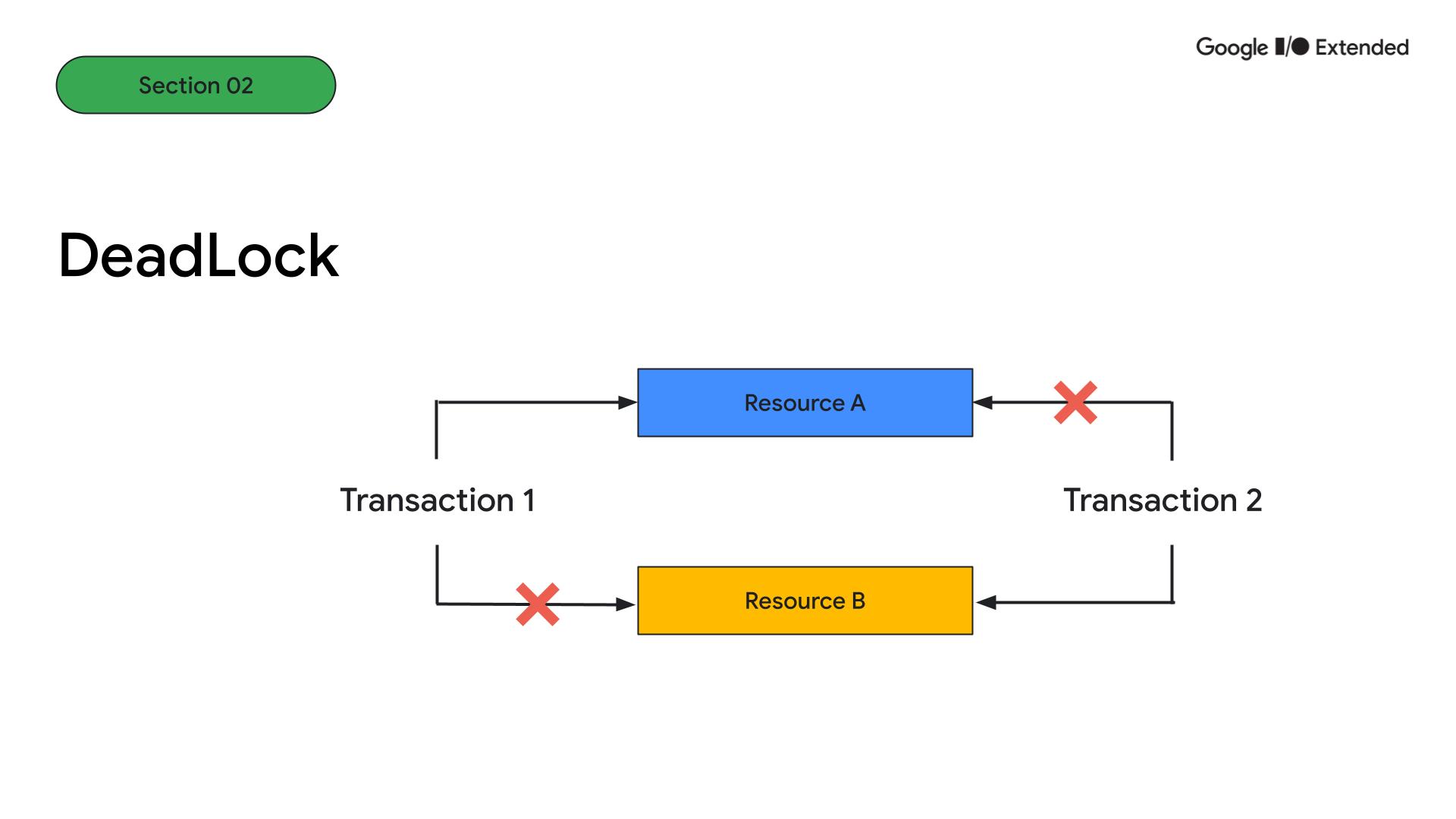
DeadLock은 두 트랜잭션이 서로 다른 리소스를 점유한 상태에서 상대 리소스 점유를 얻기 위해 기다리고 있는 교착상태입니다. Transaction 1이 Transaction 2가 점유한 리소스 B에 접근할 수 없고, 반대로 Transaction2도 리소스 A에 접근할 수 없는 상태가 되어 무한 대기가 발생하는 상황을 말합니다.
실제로 Deadlock이 발생했을 때 다음과 같은 에러가 났었습니다. 에러에서 보면 PID 61이 희생양으로 종료된 것을 볼 수 있습니다. 즉 제대로 반영되지 않고 종료되어 실제 예약이 등록되지 않은 상태로 종료되었습니다.
1
2
3
2023-02-06 11:57:33.526 WARN 3028 --- [o-8080-exec-431] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1205, SQLState: 40001
2023-02-06 11:57:33.526 ERROR 3028 --- [o-8080-exec-431] o.h.engine.jdbc.spi.SqlExceptionHelper : Transaction (Process ID 61) was deadlocked on lock | communication buffer resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
2023-02-06 11:57:33.527 ERROR 3028 --- [o-8080-exec-431] h.hsas.service.Exception Controller : ErrorResponse(location=[CannotAcquireLockException]
Deadlock 어떻게 해결할 것인가
당시에 어떻게 해결할지 많은 고민을 했고, 대기업에 근무하면서 큰 비용과 리소스를 자유롭게 운용할 수 있는 사항이 아니었기에 해결방안이 제한적이었습니다. 이 시점에서 제가 할 수 있는 조치들을 고민해보게 되었습니다. 실제로 큰 비용과 러닝커브를 들이지 않고 해결할 수 있는 방안들이기 때문에 기본적이지만 고려되어야 할 중요한 대안입니다.
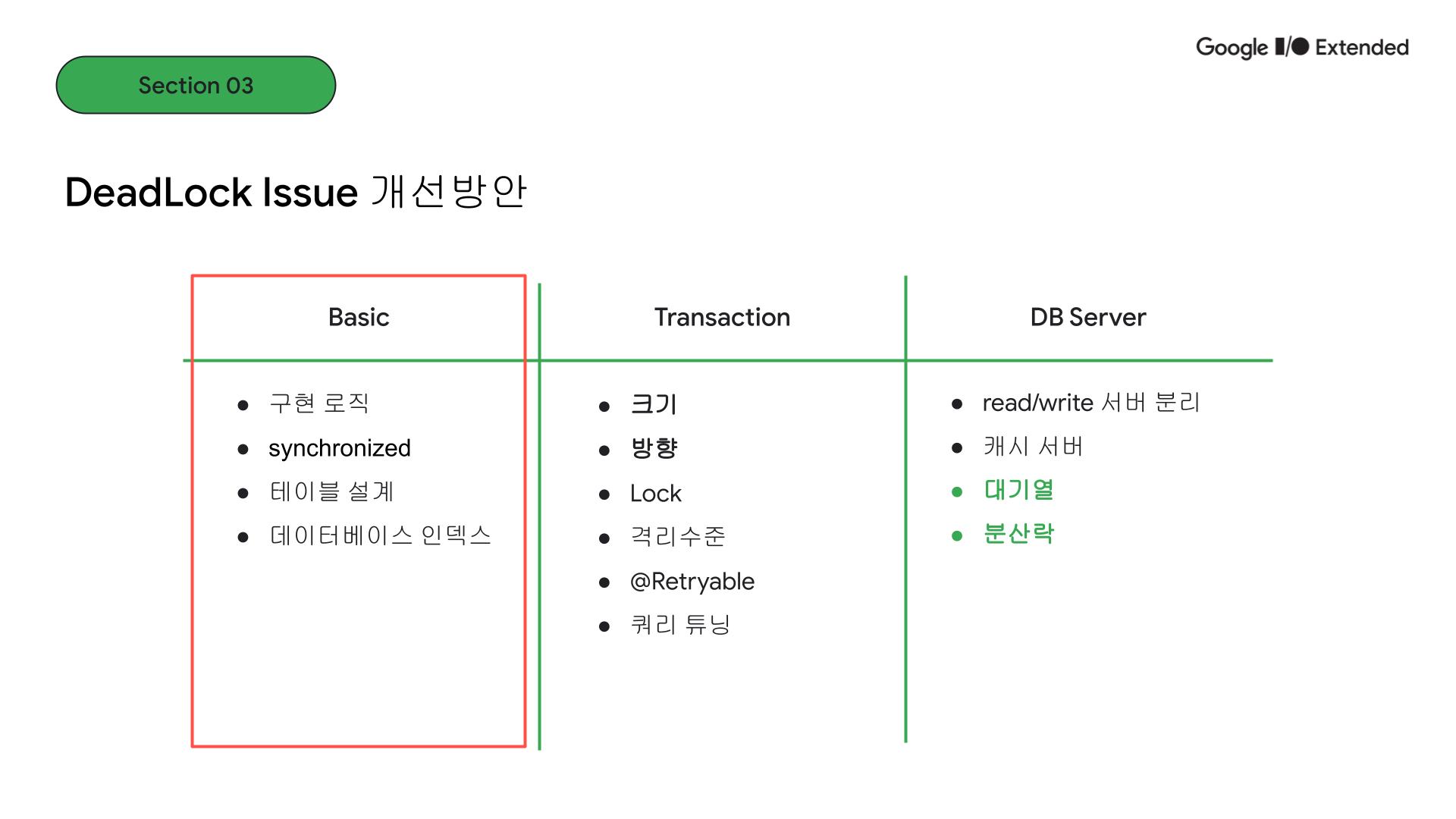
먼저 기본적인(Basic한) 부분에서 살펴보겠습니다.
코드의 구현 로직이나 테이블의 설계적 측면입니다.
예약 프로그램을 예시로 들면, 회원/관리자, 예약 신청, 후기, 등록, 기타 서비스와 같은 도메인들이 있을 수 있는데, 예약 신청이 가장 핵심 기능이고 트래픽이 몰릴 수 있다고 가정하면, 이 부분을 데이터베이스에서 읽어오거나 저장할 때 어떻게 구현되어 있는지 그리고 테이블 설계가 어떻게 되어 있는지 다시 살펴볼 필요가 있습니다.
그 다음 데이터베이스 인덱스 설정도 다시 확인해야 합니다.
Non-clustered index로 여러 컬럼들이 묶어서 하나의 인덱스 설정이 되어 있습니다. 이런 경우에는 단순히 Lock이 걸릴 때, 행 단위 row lock이 아닌 page lock이 걸릴 가능성이 높기 때문에 결국 deadlock 가능성도 높아집니다.
자바에서는 synchronized와 같이 동시성 제어를 위해 제공되는 기능이 있습니다. 다른 언어들로 따지면 뮤텍스, 락 기능입니다.
여러 요청이 있을 때 순차적으로 하나씩 메서드를 처리할 수 있도록 합니다. 하지만 이 synchronized로는 부족합니다. 단일 애플리케이션 환경에서는 문제 없지만, 분산 시스템 환경에서는 데이터 정합성을 보장받기는 어렵습니다.
트랜잭션 측면에서 고려할 사항은 어떤 것들이 있을까요?
먼저 위에 데드락 이슈를 해결하기 위해 적용했던 부분이 바로 이 트랜잭션 크기와 방향성을 일치시켜 주는 일이었습니다. 한 트랜잭션에 기능이 여러 개인 메서드가 들어가지 않도록 크기 단위를 조절할 필요가 있습니다. 트랜잭션 단위를 작게 만들어 락이 걸리는 시간이 작아지도록 할 수 있습니다.
그리고 여러 트랜잭션에서 데이터를 조회하는 메서드가 반대 순서로 진행된다면, 서로 다른 리소스를 점유하는 상황에서 데드락이 발생할 수 있습니다. 하지만 실질적으로 여러 서비스를 가진 복잡한 프로젝트에서 이렇게 간단하게 해결하기는 어려운 경우가 많습니다.
Lock이나 격리수준을 설정하는 방법도 있습니다. 간단하게 락은 여러 트랜잭션이 있을 때 동시에 접근하지 못하도록 제어하는 것이고 트랜잭션 격리수준은 어떤 트랜잭션의 변경 사항이 다른 트랜잭션에게 보이는지를 제어합니다.
Spirng JPA에서는 이렇게 락이나 격리수준을 설정하는 유용한 어노테이션을 제공하고, @Retryable을 사용해 재시도 설정도 가능합니다.
트랜잭션 단위의 쿼리가 어떻게 실제로 나가는지 확인해 볼 필요가 있습니다. 조인이 너무 많거나 조건이 너무 많다면 락의 범위가 커지면 데드락으로 이어질 수 있습니다.
트랜잭션 측면에서 고려할 사항은 어떤 것들이 있을까요?
실질적으로 앞에서 이야기한 부분은 코드를 작성하고 리펙토링 하는 과정에서 어느 정도 정리될 수 있지만 더 큰 트래픽과 확장성을 고려한다면, 시스템 설계적인 부분에서 고민해볼 필요가 있습니다.
read/write 서버의 분리입니다. 대부분의 애플리케이션은 읽기 비중이 높기 때문에 이렇게 마스터 서버를 두고 하위 replica 서버들로 읽기 요청을 처리하도록 할 수 있습니다. 이렇게 하게 되면 트래픽이 몰렸을 때 데이터베이스에 가중되는 부하를 분산시킬 수 있습니다.
성능이 빠른 인 메모리 데이터를 사용해서 캐싱 처리하는 방법도 있습니다. 캐시서버를 두는 방식으로 redis 캐싱 전략에서 look aside라는 방식을 보면, 먼저 캐시 서버에 데이터가 있는지 확인하고 캐시미스가 발생하면 디스크에서 조회 후 캐시 서버에 업데이트하고 반환하는 방식을 이용합니다. 즉, 이렇게 매번 디스크에서 데이터를 조회하지 않기 때문에 성능상에 이점이 있습니다.
마지막으로 대기열과 분산락입니다. 대기열은 리스트나 큐에 작업단위를 넣어 순차적으로 진행될 수 있도록 하는 방식입니다. 분산락은 분산시스템에서 동시성 제어를 위해 그림과 같이 락을 획득한 경우에 데이터나 자원에 접근할 수 있도록 하는 방식입니다.
Redis에 대하여
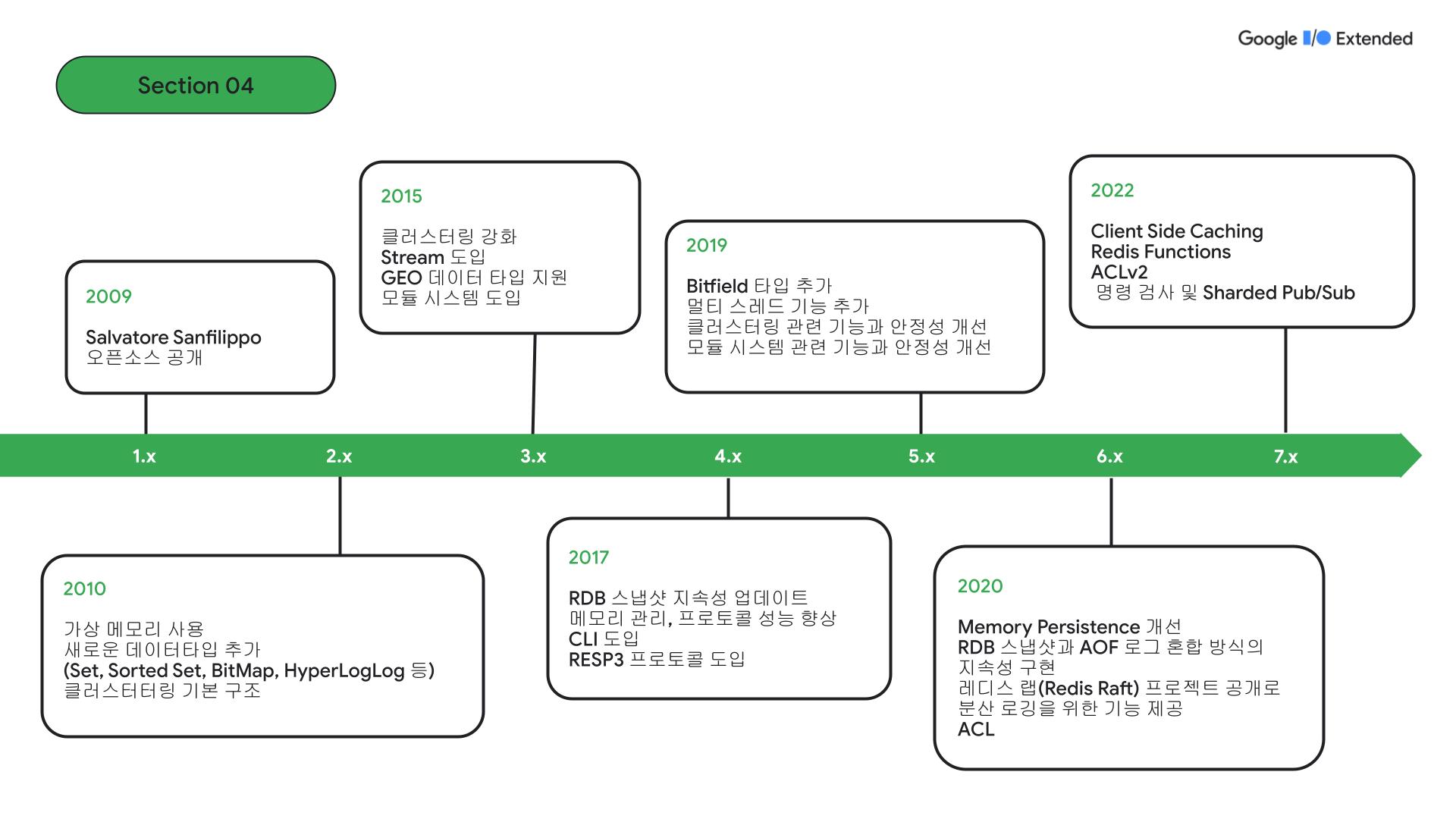
Redis Github new features를 보고 버전별로 정리한 자료입니다. 버전 7.0을 기준으로 뉴 스펙 중 가장 주목할 만한 기능은 Redis 함수, ACLv2, 명령어 내부 조사(command introspection), Sharded Pub/Sub이 있습니다.
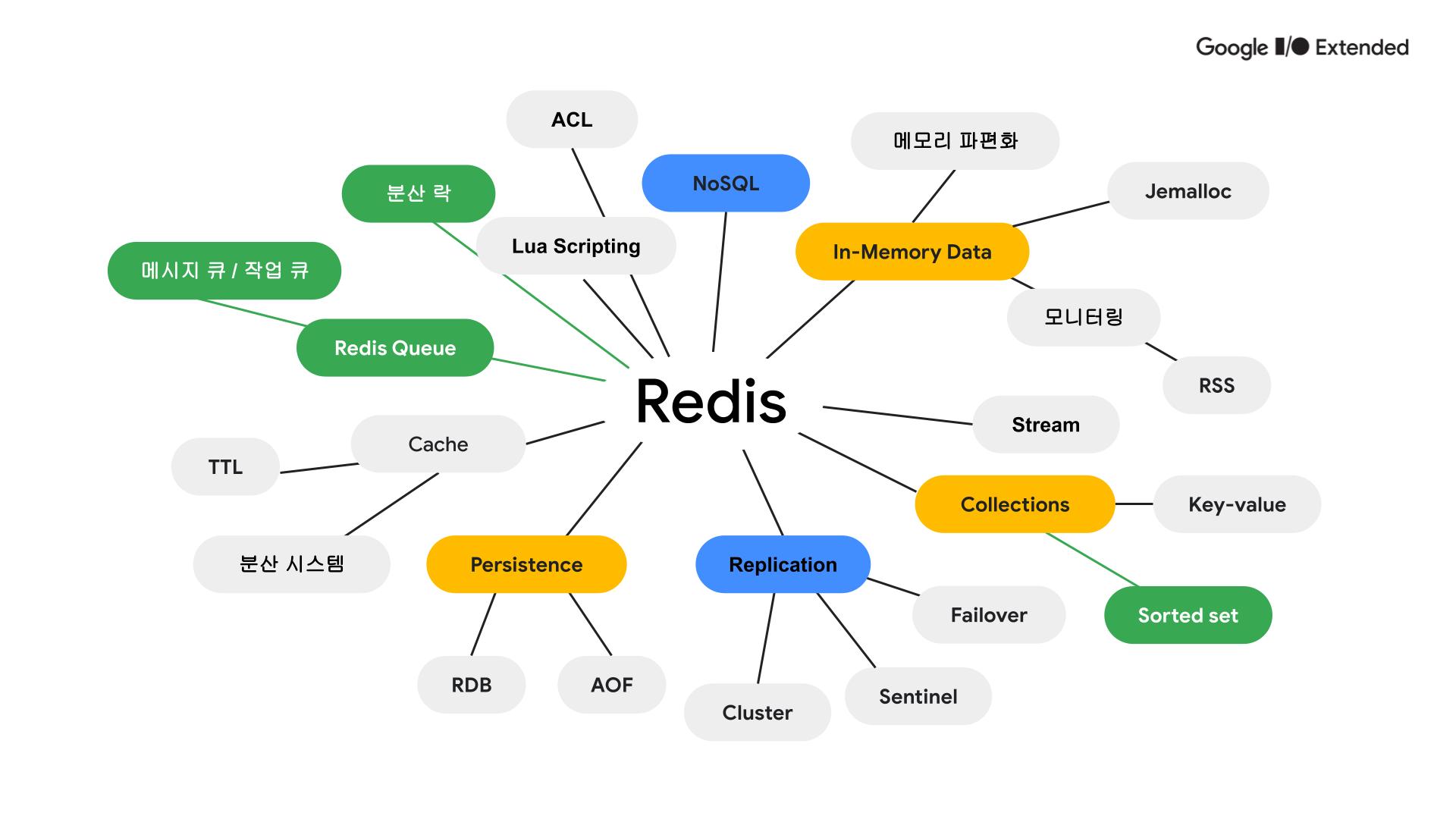
레디스는 NoSQL, In-memory 데이터베이스입니다. 그렇기 때문에 메모리 관리를 위한 모니터링을 하는 것이 중요합니다. Jmalloc으로 메모리 할당이 되며, 같은 크기의 자료를 저장하는 것이 메모리 파편화를 줄이는데 도움이 됩니다.
Redis는 Sorted set, set, hyperloglogs와 같은 다양한 자료구조를 지원합니다.
인메모리 데이터베이스이기 때문에 휘발성이 있습니다. 따라서 레디스는 이를 보완하기 위해 복제기능을 제공하는데 클러스터, 센티널과 같은 구조로 사용할 수 있습니다. 그리고 장애가 발생한 노드를 감지하고 마스터 노드로 승격시키는 failover 기능이 있습니다.
데이터 지속성을 위해 백업 스냅샷을 제공하는 RDB, 레디스 명령어를 로그 파일로 저장하는 AOF 기능이 있습니다. 둘 다 디스크 공간을 필요로 하기 때문에 적절히 조절할 필요가 있습니다.
레디스는 대표적인 캐시 서버로 분산 시스템에 사용될 수 있고, 데이터 신선도와 자원 절약을 위해 TTL 설정을 효율적으로 할 필요가 있습니다.
대기열과 분산락을 만드는데 사용되기도 하고 루아 스크립트를 사용합니다. 여러 개별 Redis 명령어를 네트워크를 통해 전송하는 대신, 루아 스크립트 하나로 여러 명령어를 한 번에 실행할 수 있습니다. 이는 네트워크 오버헤드를 줄이고 성능을 향상시킬 수 있습니다.
Redis 대기열
redis에서는 sorted set을 어떻게 관리할까요?
configuration 파일에 보면, entry가 128개 미만이고 모든 entry의 총합이 64byte 미만인 경우에는 ziplist 구조로 저장됩니다. 두 조건에서 하나만 벗어나도 skiplist 구조로 저장됩니다.
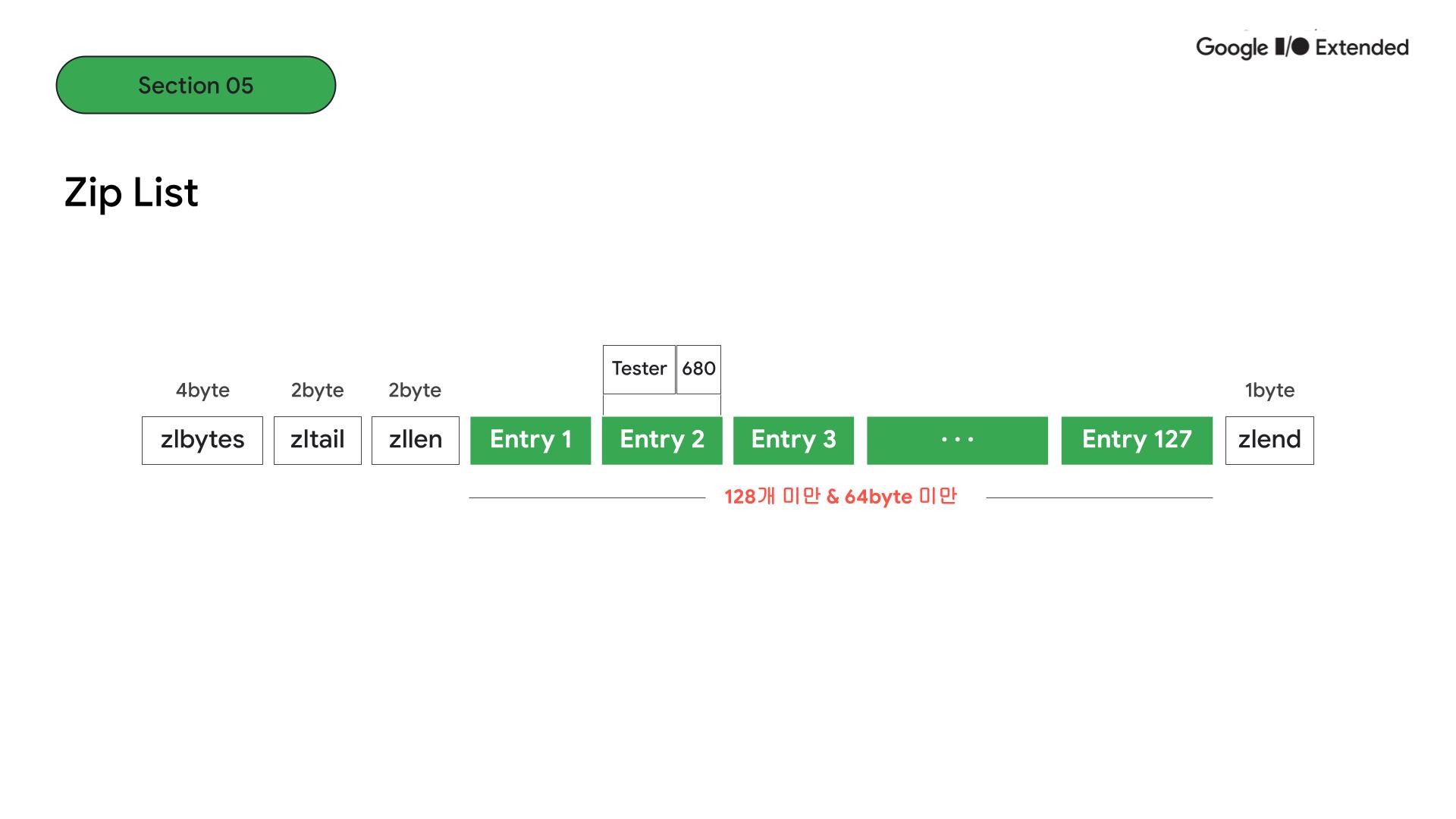
먼저 ziplist 구조를 보면, 상대적으로 entry가 작기 때문에 선형의 구조로 entry가 저장되는 것을 볼 수 있습니다. 한 entry는 값과 점수 쌍을 의미합니다.
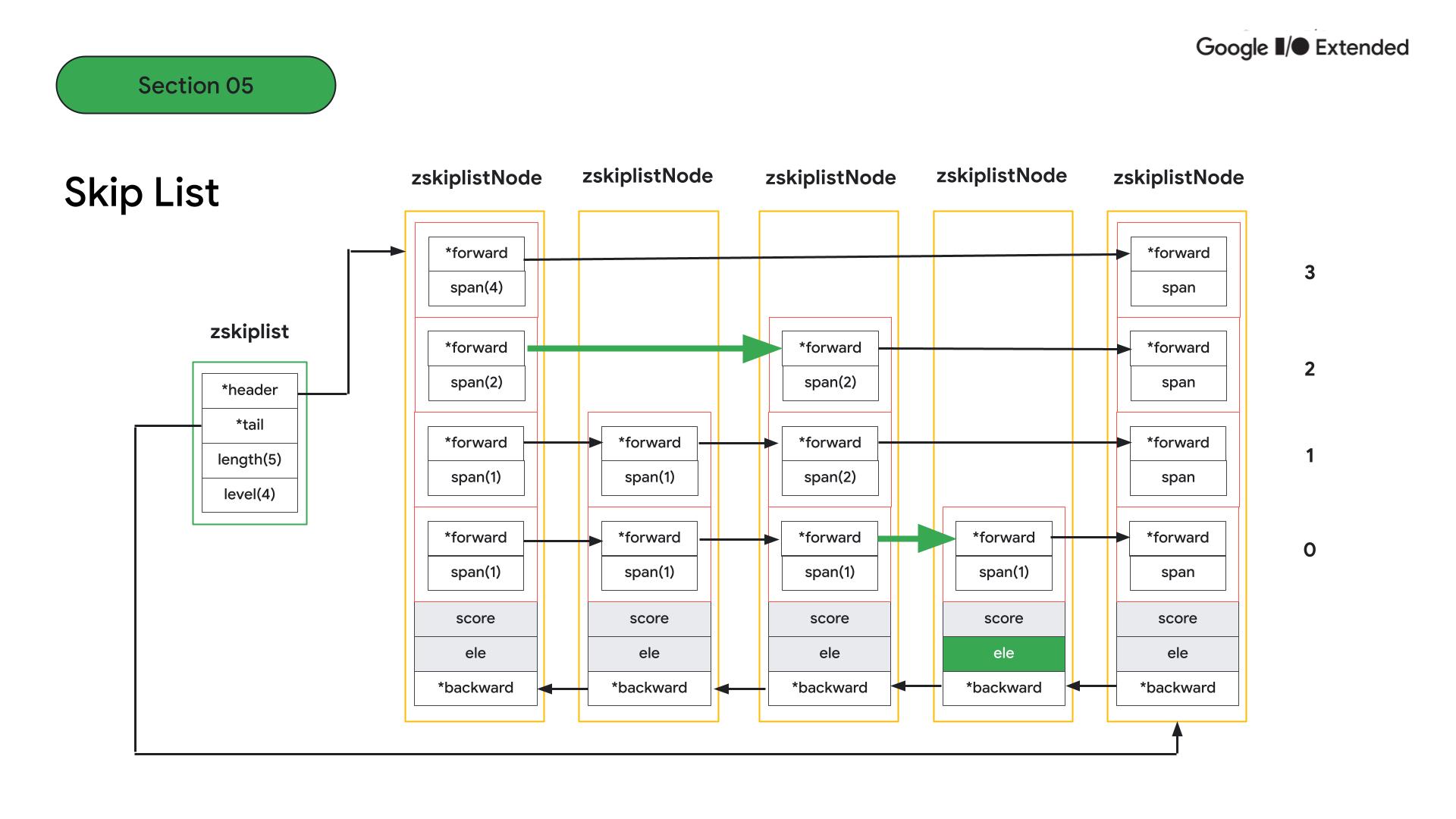
skiplist는 안에는 노드의 처음과 끝을 가리키는 header와 tail이 있고 노드의 갯수와 노드 내 level 수를 알 수 있습니다. 각 노드는 값과 점수 그리고 노드 내 레벨 안에 forward로 다음 노드를 알 수 있습니다.
예를 들어 네 번째 노드의 값 element를 찾는다고 하면, 높은 레벨에서 큰 단위로 점프한 다음, 다음 노드를 찾기 때문에 더 빠르게 검색이 가능합니다.
결과적으로 ziplist와 skiplist를 비교하면 시간복잡도 측면에서는 skiplist가 log n으로 좋지만, entry가 작거나 적고 메모리 관리가 중요한 상황에서는 ziplist를 사용하는 것이 좋습니다.
Redis 스핀락과 분산락
스핀락
스핀락은 계속 락을 얻기 위해서 계속 루프를 돌며 시도하는 락으로 부하가 커지기 때문에 루프에서 sleep 기능으로 텀을 주는 것이 좋습니다. 그리고 lock 점유시간도 작은 멀티 스레드 환경에서 사용하는 것이 좋습니다.
Spring에서는 의존성 추가로 redis 클라이언트 라이브러리 중 하나인 lettuce를 편하게 사용할 수 있습니다. Lettuce로 spin락을 구현하면 락을 획득하는 과정에서 일정시간을 두고 반복하는 기능을 제공하지 않기 때문에 락 획득 가능여부를 루프를 돌면서 체크하는 부분을 구현해야 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public boolean acquireLettuceSpinLock(String lockKey, long timeout, long startTime) throws InterruptedException {
boolean locked = redisTemplate.opsForValue().setIfAbsent(lockKey, "locked", timeout, TimeUnit.MILLISECONDS);
while (!locked && System.currentTimeMillis() - startTime < timeout) {
Thread.sleep(50);
}
if (!locked && System.currentTimeMillis() - startTime >= timeout) {
return false;
}
return locked;
}
public void releaseLock(String lockKey) {
redisTemplate.delete(lockKey);
}
반면 redisson 스핀락에서는 getSpinLock으로 RLock 객체를 얻을 수 있고, tryLock으로 반복 구문을 별도로 구현하지 않고 timeout과 단위 설정만으로 스핀락을 구현할 수 있다는 차이가 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
redisson.getSpinLock(lockKey).tryLock(timeout, timeUnit);
/**
* Returns Spin lock instance by name.
* <p>
* Implements a <b>non-fair</b> locking so doesn't guarantees an acquire order by threads.
* <p>
* Lock doesn't use a pub/sub mechanism
*
* @param name - name of object
* @return Lock object
*/
RLock getSpinLock(String name);
분산락
분산락은 분산 환경에서 여러 사용자 또는 스레드가 공유 데이터나 리소스에 접근할 때, 락을 획득해야 데이터베이스에 접근이 가능하게 합니다.
비관적 락은 단일 서버나 프로세스 내에서 데이터의 동시성을 제어하는데 사용되며, 분산 락은 여러 서버나 프로세스 사이에서 공유 리소스의 동시성을 제어하는데 사용된다는 차이가 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
redisson.getLock(lockKey).tryLock(timeout, timeUnit);
<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.singletonList(getRawName()), unit.toMillis(leaseTime), getLockName(threadId));
}
redission으로 분산락을 구현하게 되면 getLock() 메서드를 이용해 구현할 수 있습니다. 락 획득을 위해 단순히 lock() 메서드를 이용하지 않고 tryLock() 메서드를 사용하면 락 획득을 못했을 때 에러를 던지는 것이 아니라 재시도를 하게 되는데 실제 이 루아 스크립트를 redis excutor라는 클래스로 받아 redis에서 처리합니다.
성능테스트와 대용량 트래픽 해결을 위한 방안 고찰
Jmeter로 성능테스트를 진행했고 이벤트 목표 인원의 10배인 동시 접속자 수로 받는다고 했을 때, redis lettuce 스핀락, redisson 스핀락, redisson 분산락에서는 데이터가 100개로 limit에 맞게 들어온 것을 확인했습니다.
하지만 일반적인 비관적, 낙관적 락만으로는 동시성 제어가 부족함을 알 수 있었습니다.
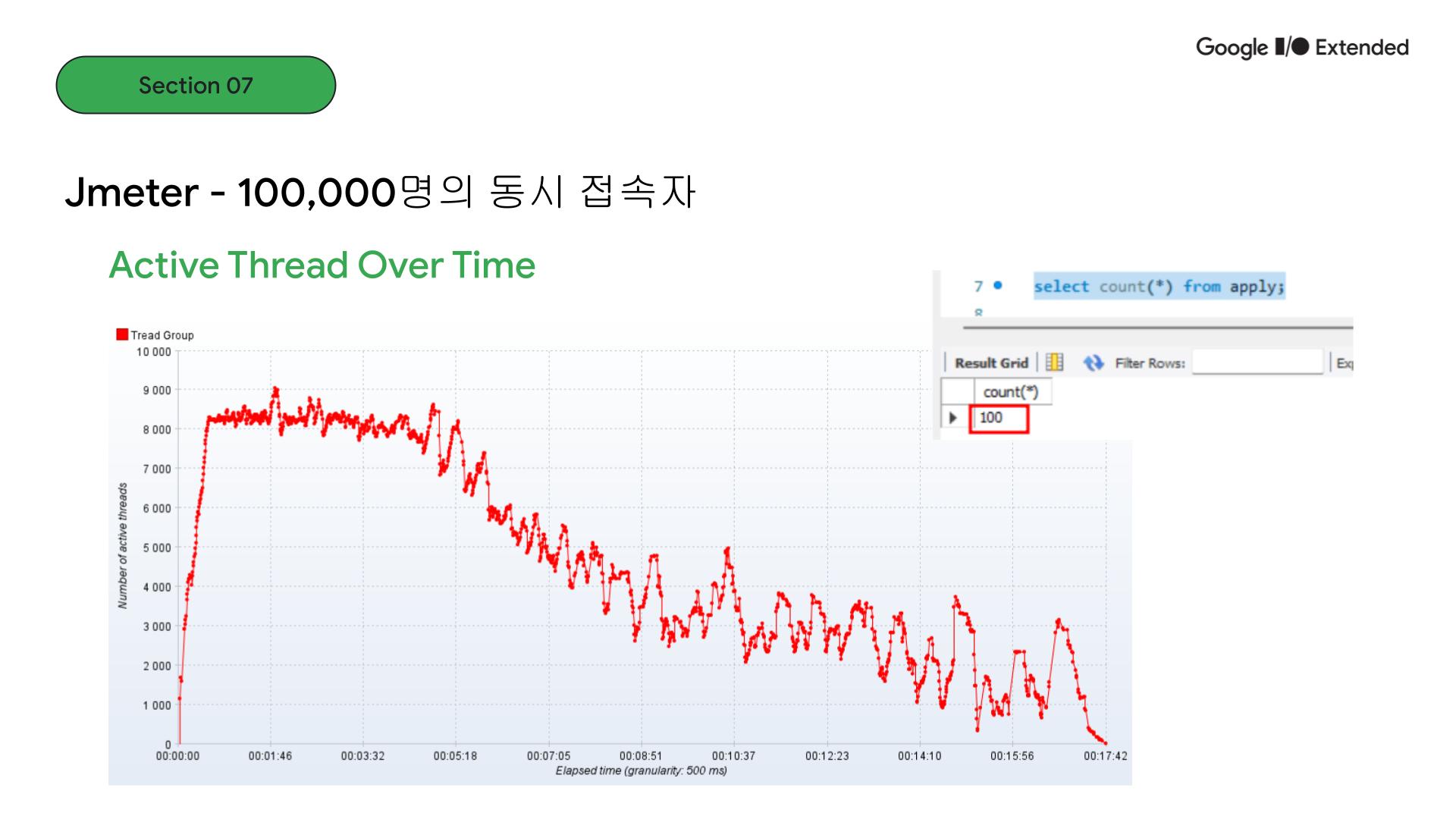
동시접속자 수가 10만일 때, 스레드 병목현상이 발생하는 것을 볼 수 있습니다. 그래도 데이터는 100개만 들어오는 것으로 정합성은 지켜지는 것을 확인할 수 있었습니다. 하지만 트래픽이 높아지니 분산락에도 이슈가 발생했습니다. Redis 서버 연결 확인을 위해 ping을 했을 때 pong 응답이 와야하는데 서버가 제대로 작동을 하지 못해 발생하는 문제였습니다. 단일 포인트인 Redis에 모든 트래픽이 쏠렸기 때문입니다.
1
2
3
4
5
6
org.apache.http.conn.HttpHostConnectException: Connect to localhost:8080 [localhost/127.0.0.1, localhost/0:0:0:0:0:0:0:1] failed: Connection refused: connect at org.apache.http.impl.conn.DefaultHttpClientConnectionOperator.connect(DefaultHttpClientConnectionOperator.java:156) at org.apache.jmeter.protocol.http.sampler.HTTPHC4Impl$JMeterDefaultHttpClientConnectionOperator.connect(HTTPHC4Impl.java:409) at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.connect(PoolingHttpClientConnectionManager.java:376) at
org.redisson.client.RedisTimeoutException: Command execution timeout for command: (PING), params: [], Redis client: [addr=redis://localhost:6379]
at org.redisson.client.RedisConnection.lambda$async$0(RedisConnection.java:244) ~[redisson-3.18.0.jar:3.18.0]
at io.netty.util.HashedWheelTimer$HashedWheelTimeout.run(HashedWheelTimer.java:715) ~[netty-common-4.1.94.Final.jar:4.1.94.Final]
at io.netty.util.concurrent.ImmediateExecutor.execute(ImmediateExecutor.java:34) ~[netty-common-4.1.94.Final.jar:4.1.94.Final]
그럼 분산락의 한계는 어떻게 해결해야 할까요?
단일 장애지점이 된 redis 구조를 클러스터나 센티날로 변경해서 처리할 수 있습니다. 메모리 모니터링, 로그 레벨 등을 통해 미리 확인하고 주의해야할 이슈를 알림으로 받아보는 등의 관리가 필요합니다. 분산락을 얻기 위해 대기하는 시간을 줄이는 timeout 설정을 고려할 수도 있을 것입니다. 서비스 크기나 비용 지원이 가능하다면 이벤트 브로커를 활용하는 것도 대안이 될 수 있습니다.